学习笔记,非纯原创。推荐配合「JVM 101 - 内存管理」一文阅读。
1. JVM 概览
Java 代码有很多种不同的运行方式。比如说可以在开发工具中运行,可以双击执行 jar 文件运行,也可以在命令行中运行,甚至可以在网页中运行。这些执行方式都离不开 JVM。
名词解析
- JVM: Java Virtual Machine,用于执行 Java bytecode。可以由硬件实现,但更为常见的是在各个现有平台(如 Windows_x64、Linux_aarch64)上提供软件实现。是 Java 实现 “Write Once,Run Anywhere”(跨平台)的根本原因。
- JRE: Java Runtime Environment = JVM + Java 核心类库。支持 Java 运行 (run) 的标准环境。
- JDK: Java Development Kit = JRE + Dev Tool。用于支持 Java 开发 (develop) 的最小环境。
虚拟机以及大量建立在虚拟机之上的程序语言如雨后春笋般出现并蓬勃发展,把程序编译成二进制本地机器码(Native Code)已不再是唯一的选择,越来越多的程序语言选择了与操作系统和机器指令集无关的、平台中立的格式作为程序编译后的存储格式。各种不同平台的 JVM,以及所有平台都统一支持的程序存储格式——字节码(Byte Code)是构成平台无关性的基石。
JVM 的语言无关性
在 Java 技术发展之初,设计者们就曾经考虑过并实现了让其他语言运行在 JVM 之上的可能性,他们在发布规范文档的时候,也刻意把 Java 的规范拆分成了《Java语言规范》(The Java Language Specification)及《Java虚拟机规范》(The Java Virtual Machine Specification)两部分。JVM 不与包括 Java 语言在内的任何程序语言绑定,它只与“Class文件”这种特定的二进制文件格式所关联。Class文件中包含了Java虚拟机指令集、符号表以及若干其他辅助信息。作为一个通用的、与机器无关的执行平台,任何语言的实现者都可以将 JVM 作为他们语言的运行基础,以 Class 文件作为他们产品的交付媒介。
时至今日,商业企业和开源机构已经在Java语言之外发展出一大批运行在 JVM 之上的语言, 如Kotlin、Clojure、Groovy、JRuby、JPython、Scala等。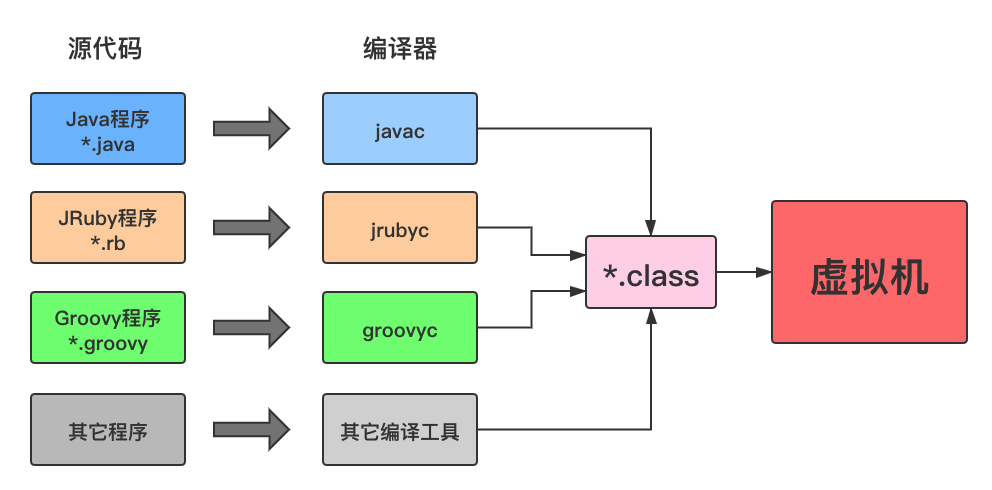
2. 概述:Java 源文件是怎样跑起来的
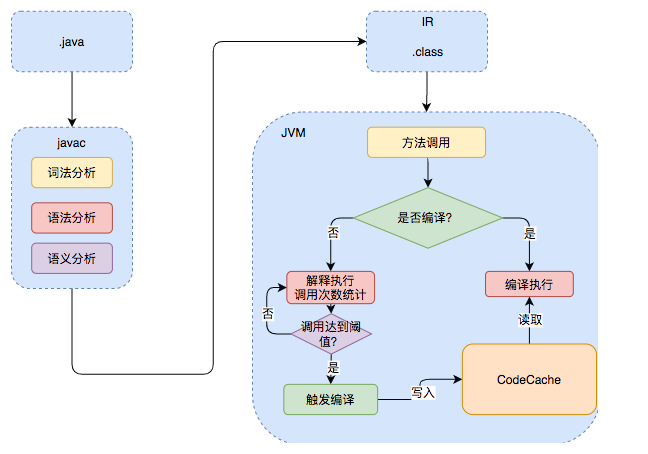
Java 源码的运行过程整体可以分为两个部分:
- 由 Javac 将源码编译成字节码,在这个过程中会进行词法分析、语法分析、语义分析,编译原理中这部分的编译称为
前端编译。 - 接下来直接逐条将字节码
解释执行,在解释执行的过程中,虚拟机同时对程序运行的信息进行收集,在这些信息的基础上,编译器会逐渐发挥作用,它会进行后端编译 ——把字节码编译成机器码并执行。但只有被 JVM 认定为的热点代码才能被编译。
热点代码
怎么样才会被认为是热点代码呢?JVM 中会设置一个阈值,当方法或者代码块的在一定时间内的调用次数超过这个阈值时就会被编译,存入 codeCache 中。当下次执行时,再遇到这段代码,就会从codeCache 中读取机器码,直接执行,以此来提升程序运行的性能。整体的执行过程如上图所示。
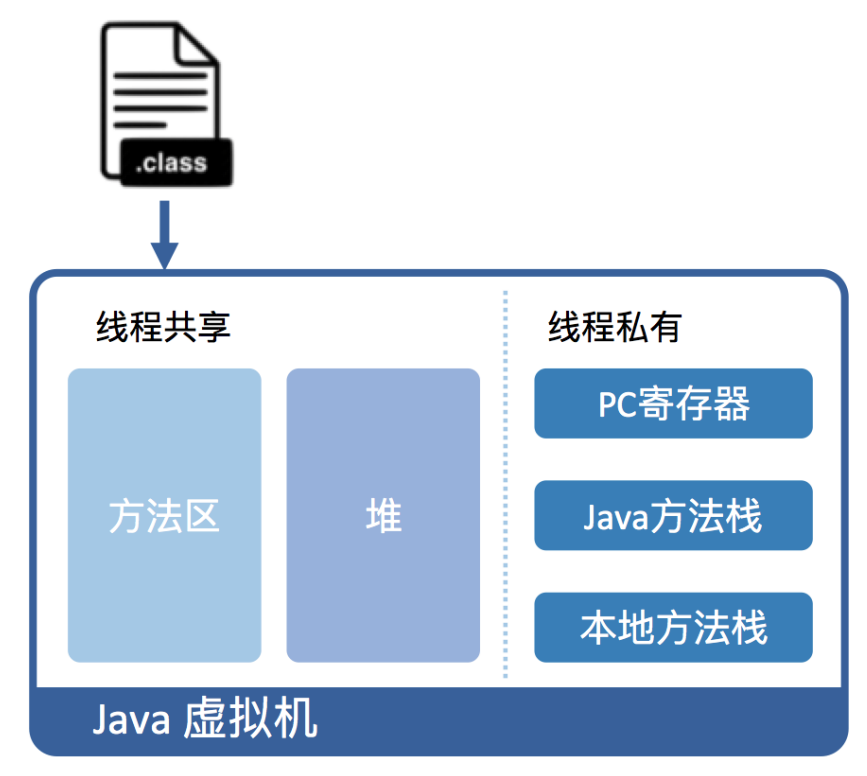
从 JVM 层面来看,执行 Java 代码首先需要将它编译而成的 class 文件加载到 JVM 中。加载后的 Java 类会被存放于方法区(Method Area)里。实际运行时,虚拟机会执行其中的代码,见下图:
从硬件层面来看,Java bytecode 无法直接执行 —— JVM 需要将 bytecode 翻译成 machine code(见下图),这包括两种形式:
解释执行,即逐条将字节码翻译成机器码并执行,优势在于无需等待编译。即时编译(Just-In-Time compilation,JIT)执行,即将一个方法中包含的所有字节码编译成机器码后再执行,优势在于实际运行速度更快。
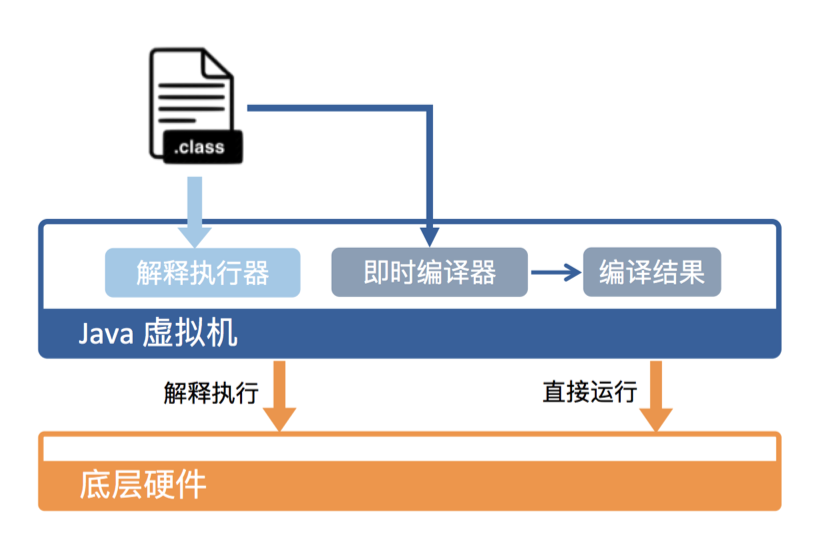
HotSpot 默认采用混合模式,综合了解释执行和即时编译两者的优点。它会先解释执行字节码,而后将其中反复执行的热点代码,以方法为单位进行即时编译。
无论是基于物理机,JVM,亦或是其他的高级语言虚拟机(High Level Language Virtual Machine, HLLVM),现代高级编程语言的执行流程都大同小异。在逻辑上基本不出下图的框架:在执行前先对程序源码进行词法分析和语法 分析处理,把源码转化为抽象语法树(Abstract Syntax Tree,AST)。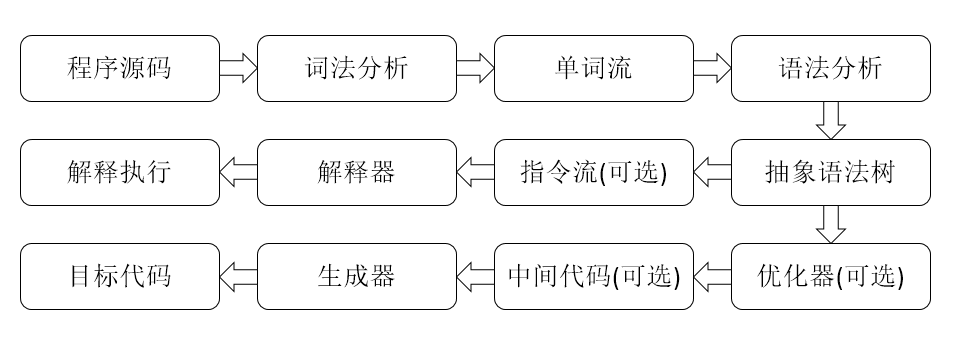
最下面那行对应编译执行,中间那行对应解释执行。而中间那行中的”指令流”一步指的是 javac 编译器生成 .class 文件的过程了。
3. 深入:解释执行
3.1. 基于栈的指令集与基于寄存器的指令集
JVM 基本上是一种基于栈的指令集架构(Instruction Set Architecture, ISA),指令依赖 方法区-局部变量表-操作数栈 进行工作。之所以说基本上,是因为纯粹的基于栈的指令集架构中的指令应该全部都是零地址指令,或者说是不带参数的指令。而 JVM 的指令集中有小部分指令是需要参数的。之所以做这个变通,是为了提高代码的可校验性。
与基于栈的指令集架构相对的另一套同样很常用的指令集架构是基于寄存器的指令集架构。最典型的就是x86的二地址指令集架构,或者更通俗的说,就是现在主流的PC微型机中直接支持的指令集架构,其中的指令依赖寄存器进行工作。
举个例子,如果要计算 1+1 的结果,那么对于 JVM 中的基于栈的指令集而言是这样的:
iconst_1 // 将1压入操作数栈
iconst_1 // 将1压入操作数栈
iadd // 弹出操作数栈栈顶的两个 int 型元素求和后,再将 int 型结果压回操作数栈
istore_0 // 将操作数栈栈顶的 int 型元素弹出并存入局部变量表索引为 0 的 slot 中如果是针对基于寄存器的指令集架构的 pc 机而言,则是:
mov eax, 1 // 将 eax 寄存器的值设为 1
add eax, 1 // 将 eax 寄存器中的值加 1 并存回 eax 寄存器栈 VS 寄存器
基于寄存器的指令集中所使用的
寄存器往往由物理机在硬件上直接提供(之所以说往往,是因为也有基于虚拟机寄存器的例子。例如 Google Android 平台的 Dalvik VM。不过即便是基于虚拟机寄存器,也希望把虚拟机寄存器尽量映射到物理寄存器上以获得更高的性能),这就不可避免的会受到硬件的约束。例如,32位80x86体系(主流PC机)的 CPU 提供了 8 个 32 位的寄存器,而 ARM(主流手机)的 CPU 则提供了 16 个 32 位的通用寄存器。若使用基于寄存器架构的指令集,用户在编写指令时必须针对不同的物理寄存器设计不同的代码。基于栈的指令集较之基于寄存器的指令集最大的优势就在于
栈更为抽象,屏蔽了这些底层的细节,具体的底层实现则交由虚拟机完成,所以易于移植。但栈架构所用的指令往往要比寄存器架构所用的指令多,因为虚拟机总归是要跑在物理机上的,而物理机又大多是基于寄存器的,因此最终干活的依然是寄存器。换句话说,栈架构相当于在寄存器架构的基础上为了便于迁移和理解加入了新的操作,自然就更长了。同时栈并不是物理机实际提供的一个硬件,它只是存在于内存中的一个抽象概念,使用栈意味着指令中的那些出栈入栈其实都是 CPU 在与内存交互,频繁的内存-缓存-寄存器间数据的流动增加了额外的开销。不过这里的执行速度是要局限在解释执行的状态下,如果经过即时编译器输出成物理机上的汇编指令流,那就与虚拟机采用哪种指令集架构没有什么关系了。
3.2. JVM 的解释执行过程
public class Test {
public int calc() {
int a = 100;
int b = 200;
int c = 300;
return (a + b) * c;
}
}然后我们用 javap 将这段代码反编译,我们只看其中的 calc() 方法的 Code 属性:
public int calc();
Code:
stack=2, locals=4, args_size=1
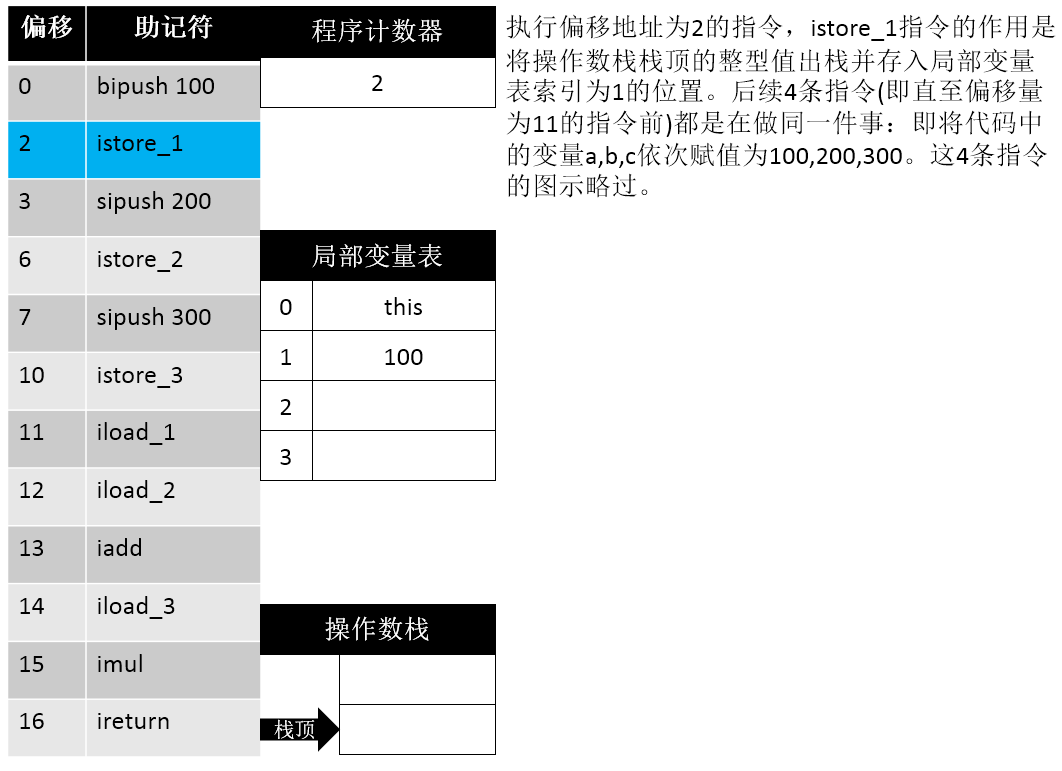
0: bipush 100
2: istore_1
3: sipush 200
6: istore_2
7: sipush 300
10: istore_3
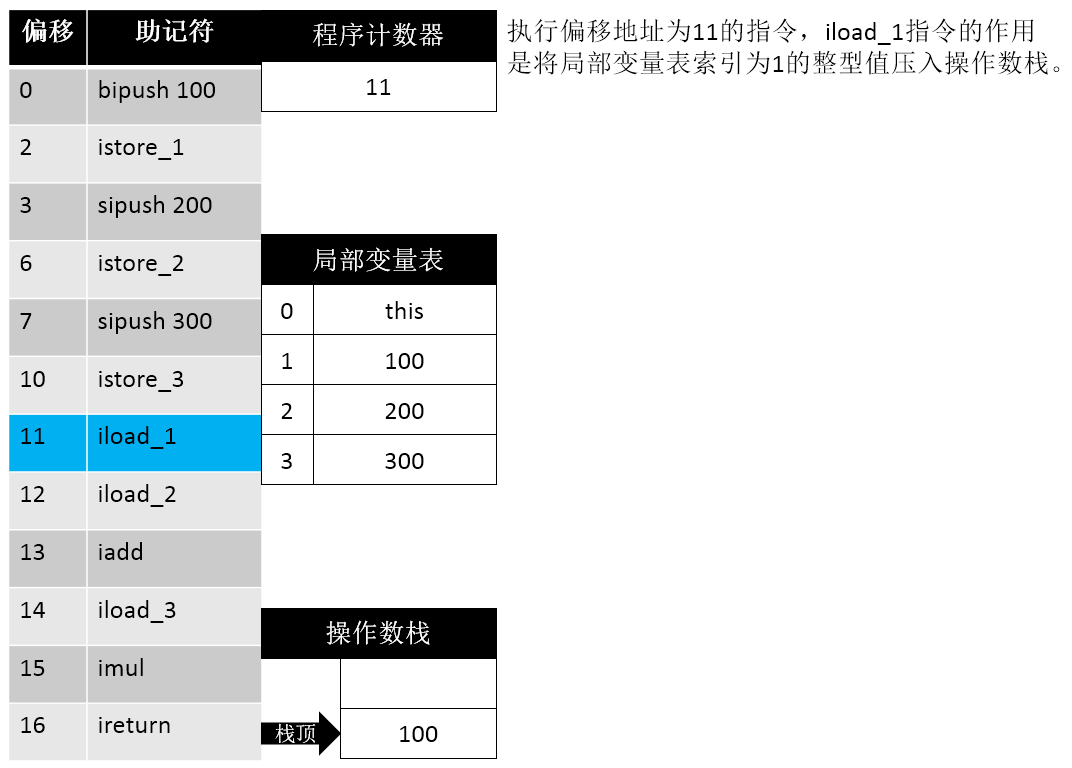
11: iload_1
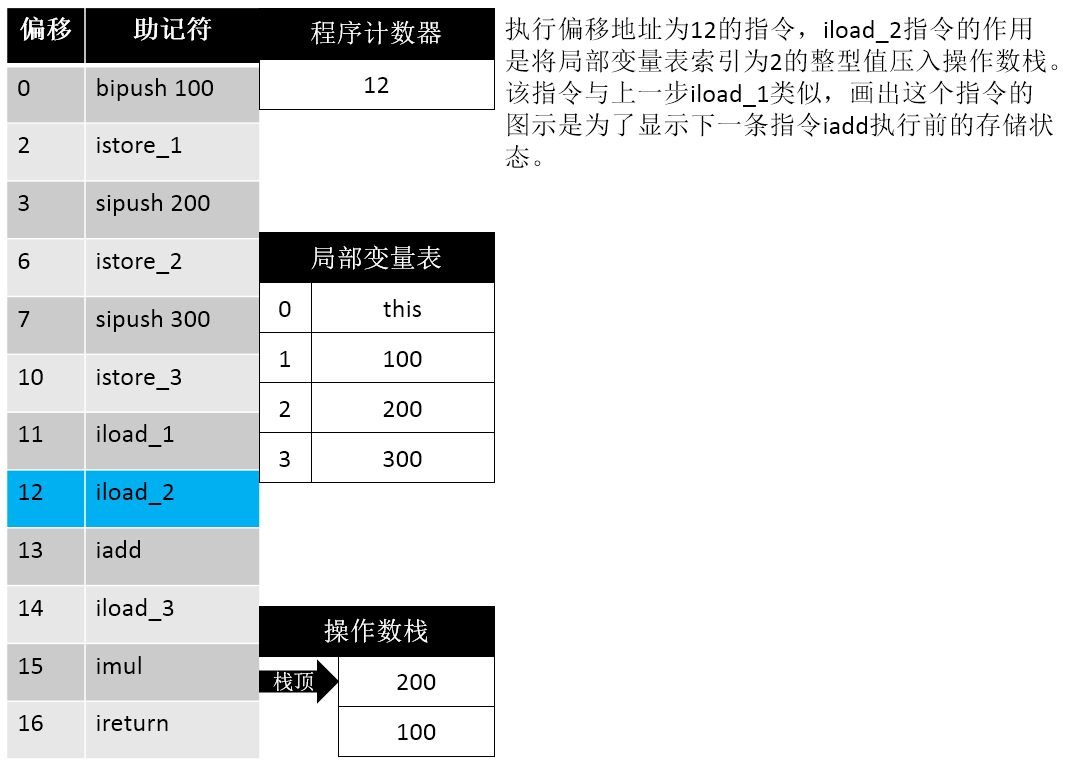
12: iload_2
13: iadd
14: iload_3
15: imul
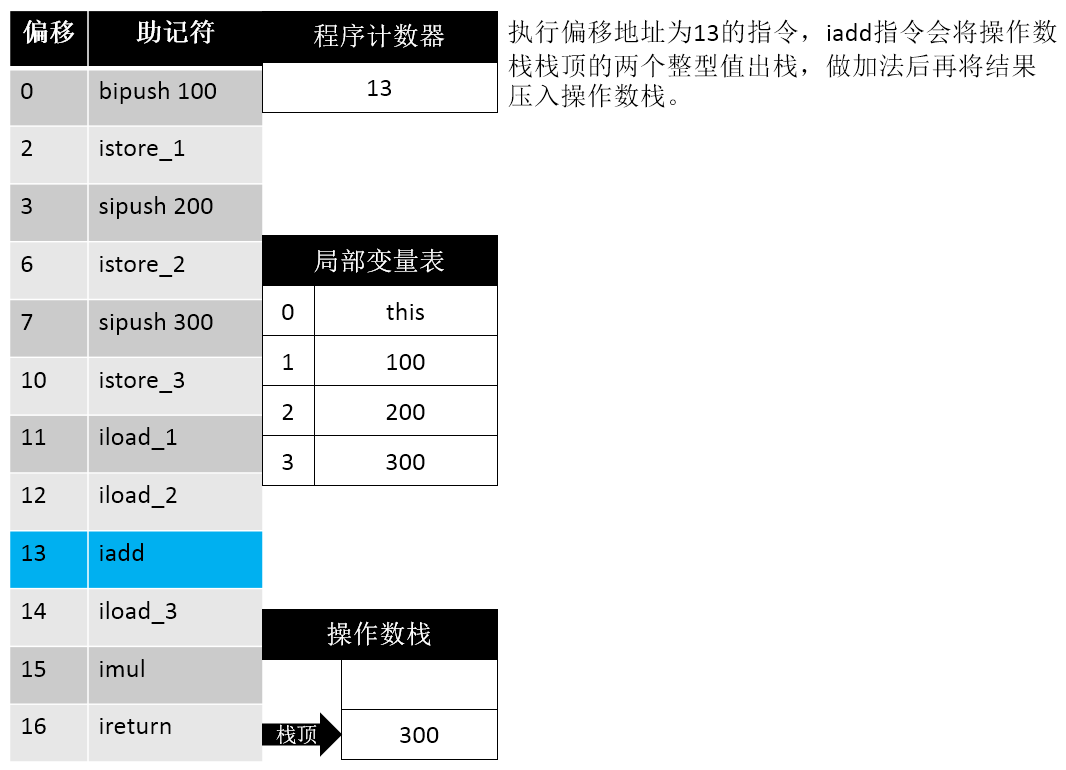
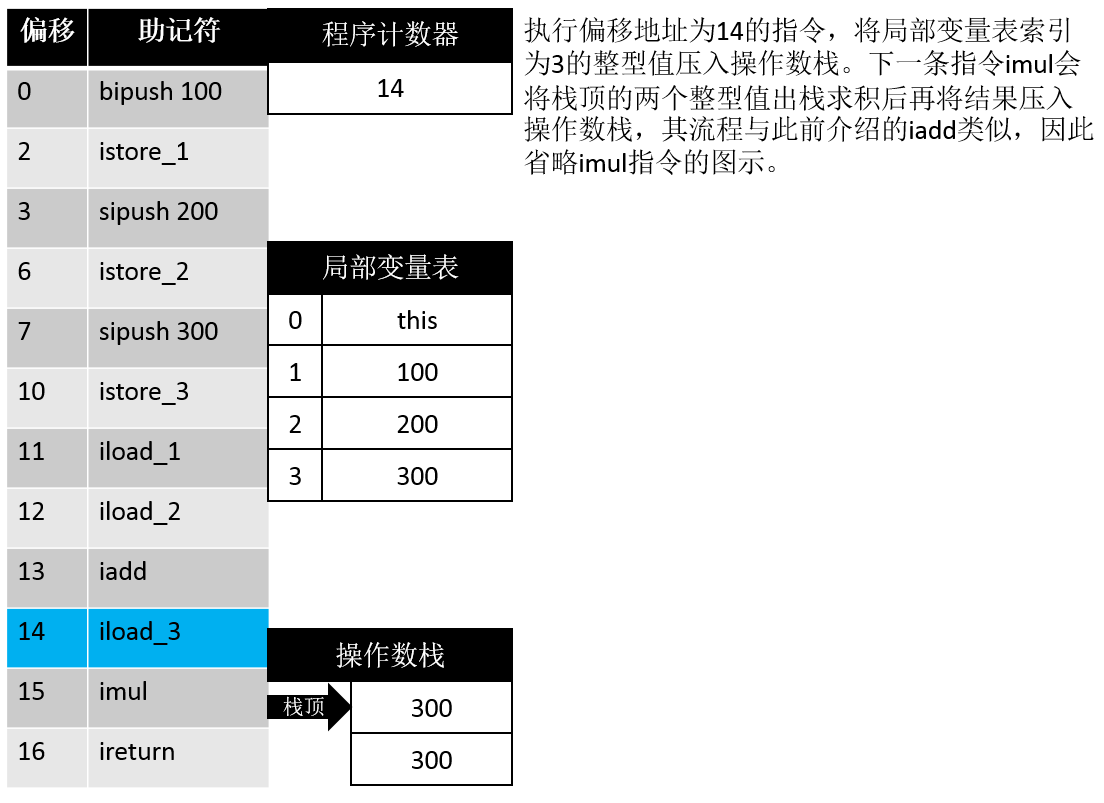
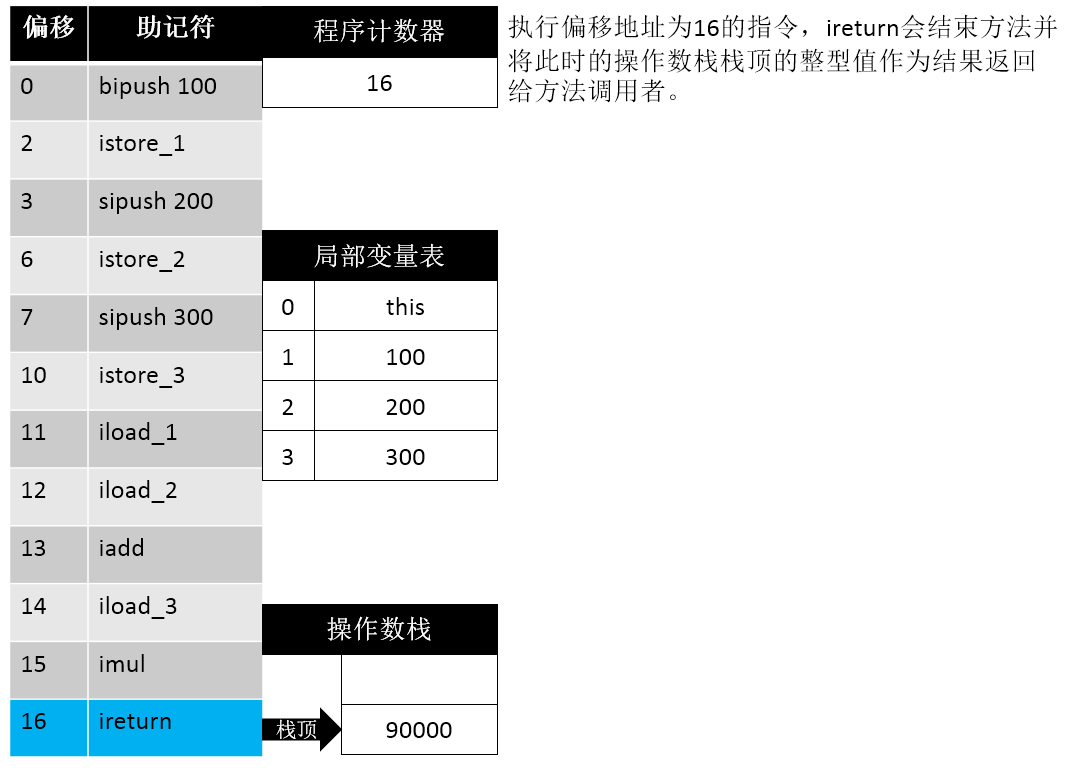
16: ireturn这段信息首先告诉我们 操作数栈的最大深度为 2,局部变量表的长度为 4 个Slot,传入参数个数为 1 (this)。据此我们可以画出如下的步骤示意图:
理论 vs 现实
需要说明的是,下面的过程仅仅是理论上的概念模型,而大多数的 JVM 实现都会做一些优化来提高性能,因此实际运行起来通常不会与这个概念模型完全相同。其实更准确的说,主流 JVM 的实际情况会与这个概念模型的差别非常大。例如 HotSpot 的指令集中有很多以 ”fast_” 开头的非标准字节码指令用于合并,替换输入的字节码以提升解释执行的性能。而对于 JIT 编译器而言,优化的手段就更加花样繁多了。

4. 深入:JIT 编译
即时编译建立在程序符合 二八定律 的假设上,也就是 20% 的代码占据了 80% 的计算资源。对于占据大部分的不常用的代码,我们无需耗费时间将其编译成机器码,而是采取解释执行的方式运行;另一方面,对于仅占据小部分的热点代码,我们则可以将其编译成机器码,以达到理想的运行速度。
运行效率
理论上讲,即时编译后的 Java 程序的执行效率,是可能超过 C++ 程序的。这是因为与静态编译相比,即时编译拥有程序的运行时信息,并且能够根据这个信息做出相应的优化。举个例子,我们知道虚方法是用来实现面向对象语言多态性的。对于一个虚方法调用,尽管它有很多个目标方法,但在实际运行过程中它可能只调用其中的一个。这个信息便可以被即时编译器所利用,来规避虚方法调用的开销,从而达到比静态编译的 C++ 程序更高的性能。
4.1. JIT 编译器
JVM中集成了两种编译器,Client Compiler 和 Server Compiler,它们的作用也不同。Client Compiler 注重启动速度和局部的优化,Server Compiler 则更加关注全局的优化,性能会更好,但由于会进行更多的全局分析,所以启动速度会变慢。两种编译器有着不同的应用场景,在虚拟机中同时发挥作用。
实例:Hotspot 编译器
HotSpot 内置了多个即时编译器:C1、C2 和 Graal。之所以引入多个即时编译器,是为了在编译时间和生成代码的执行效率之间进行取舍。
从 Java 7 开始,HotSpot 默认采用 分层编译(Tiered Compilation)的方式:热点方法先会被 C1 编译,而后热点方法中的热点会再被 C2 编译。
为了不干扰应用的正常运行,HotSpot 的即时编译是放在额外的编译线程中进行的。HotSpot 会根据 CPU 的数量设置编译线程的数目,并且按 1:2 的比例配置给 C1 及 C2 编译器。在计算资源充足的情况下,字节码的解释执行和即时编译可同时进行。编译完成后的机器码会在下次调用该方法时启用,以替换原本的解释执行。
4.1.1. Client Compiler
HotSpot 带有一个 Client Compiler C1编译器。这种编译器 启动速度快,面向的是对启动性能有要求的客户端 GUI 程序,采用的优化手段相对简单,因此编译时间较短,但是性能比较 Server Compiler 来说会差一些。 具体来说 C1 会做三件事:
- 局部简单可靠的优化,比如字节码上进行的一些基础优化,方法内联、常量传播等,放弃许多耗时较长的全局优化。
- 将字节码构造成高级中间表示(High-level Intermediate Representation,以下称为HIR),HIR与平台无关,通常采用图结构,更适合JVM对程序进行优化。
- 最后将HIR转换成低级中间表示(Low-level Intermediate Representation,以下称为LIR),在LIR的基础上会进行寄存器分配、窥孔优化(局部的优化方式,编译器在一个基本块或者多个基本块中,针对已经生成的代码,结合CPU自己指令的特点,通过一些认为可能带来性能提升的转换规则或者通过整体的分析,进行指令转换,来提升代码性能)等操作,最终生成机器码。
4.1.2. Server Compiler
在 Hotspot 中,默认的 Server Compiler 是 C2 编译器。它面向的是对峰值性能有要求的服务器端程序,采用的优化手段相对复杂,因此编译时间较长,但同时生成代码的执行效率较高。
C2 编译器在进行编译优化时,会使用一种控制流与数据流结合的图数据结构,称为 Ideal Graph。 Ideal Graph 表示当前程序的数据流向和指令间的依赖关系,依靠这种图结构,某些优化步骤(尤其是涉及浮动代码块的那些优化步骤)变得不那么复杂。
Ideal Graph 的构建是在解析字节码的时候,根据字节码中的指令向一个空的 Graph 中添加节点,Graph中的节点通常对应一个指令块,每个指令块包含多条相关联的指令,JVM会利用一些优化技术对这些指令进行优化,比如 Global Value Numbering、常量折叠等,解析结束后,还会进行一些死代码剔除的操作。生成 Ideal Graph 后,会在这个基础上结合收集的程序运行信息来进行一些全局的优化,这个阶段如果 JVM 判断此时没有全局优化的必要,就会跳过这部分优化。
无论是否进行全局优化,Ideal Graph 都会被转化为一种更接近机器层面的 MachNode Graph,最后编译的机器码就是从 MachNode Graph 中得的,生成机器码前还会有一些包括寄存器分配、窥孔优化等操作。关于Ideal Graph和各种全局的优化手段会在后面的章节详细介绍。Server Compiler编译优化的过程如下图所示:
4.1.3. Graal Compiler
从 JDK 9 开始,Hotspot 中集成了一种新的 Server Compiler,Graal 编译器。相比 C2 编译器,Graal 有这样几种关键特性:
- 前文有提到,JVM 会在解释执行的时候收集程序运行的各种信息,然后编译器会根据这些信息进行一些基于预测的激进优化,比如分支预测,根据程序不同分支的运行概率,选择性地编译一些概率较大的分支。Graal 比 C 2更加青睐这种优化,所以 Graal 的峰值性能通常要比 C2 更好。
- 使用 Java 编写,对于 Java 语言,尤其是新特性,比如 Lambda、Stream 等更加友好。
- 更深层次的优化,比如虚函数的内联、部分逃逸分析等。
Graal 编译器可以通过 JVM 参数 -XX:+UnlockExperimentalVMOptions -XX:+UseJVMCICompiler 启用。当启用时,它将替换掉 HotSpot 中的 C2 编译器,并响应原本由 C2 负责的编译请求。
4.2. 分层编译
在 Java 7 以前,需要研发人员根据服务的性质去选择编译器。对于需要快速启动的,或者一些不会长期运行的服务,可以采用编译效率较高的 C1,对应参数 -client。长期运行的服务,或者对峰值性能有要求的后台服务,可以采用峰值性能更好的 C2,对应参数 -server。Java 7 开始引入了分层编译的概念,它结合了 C1 和 C2 的优势,追求启动速度和峰值性能的一个平衡。分层编译将 JVM 的执行状态分为了 0 - 4 共 5 个层次,如下图所示:
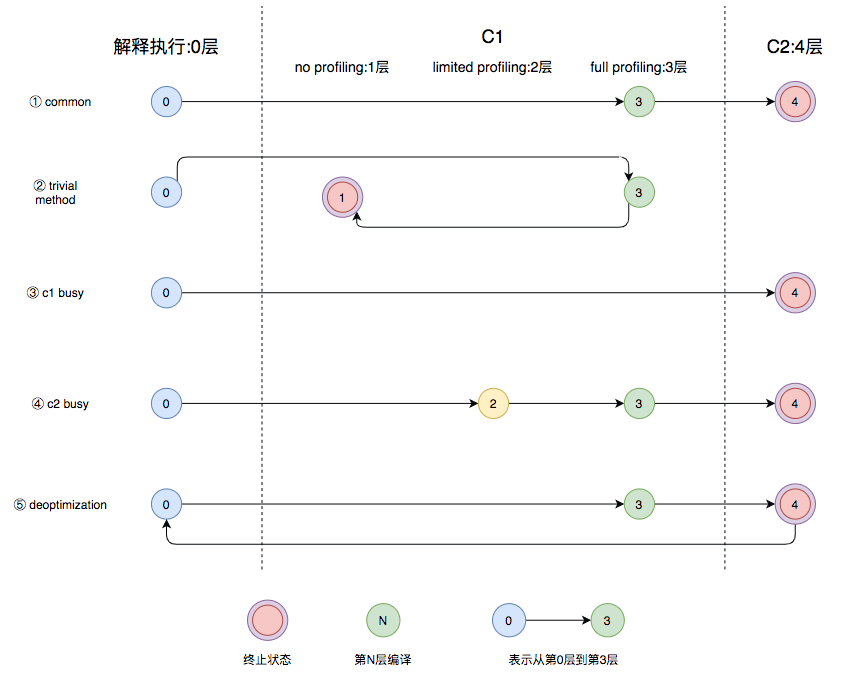
1 层和 4 层是终止状态:当一个方法被终止状态编译后,如果编译后的代码没有失效,那么 JVM 不会再次发出该方法的编译请求。Common:通常情况下,热点方法会被 3 层的 C1 编译,然后再被 4 层的 C2 编译。Trival method:如果方法的字节码数目较少(如getter/setter),且 3 层的 profiling 没有可收集的数据,JVM 会断定该方法对于 C1 和 C2 的执行效率相同,JVM 会在 3 层的 C1 编译后,直接选用 1 层的 C1 编译,由于 1 层是终止状态,JVM 不会继续用 4 层的 C2。C1 busy:在C1忙碌的情况下,JVM在解释执行过程中对程序进行profiling,而后直接由4层的C2编译。C2 busy:在C2忙碌的情况下,方法会被2层的C1编译,然后再被3层的C1编译,以减少方法在3层的执行时间。Deoptimization:如果编译器做了一些比较激进的优化,比如分支预测,在实际运行时发现预测出错,这时就会进行反优化,重新进入解释执行,图中第⑤条执行路径代表的就是反优化。
profiling
profiling 就是收集能够反映程序执行状态的数据。其中最基本的统计数据就是方法的调用次数,和循环回边的执行次数。
4.3. 触发 JIT 编译
JVM 根据方法的调用次数以及循环回边的执行次数来触发即时编译。循环回边 是一个控制流图中的概念,程序中可以简单理解为往回跳转的指令,比如下面这段代码:
public void add(Object obj) {
int sum = 0;
for (int i = 0; i < 200; i++) {
sum += i;
}
}上面这段代码经过编译生成下面的字节码。其中,偏移量为 18 的字节码将往回跳至偏移量为 4 的字节码中。在解释执行时,每当运行一次该指令,Java虚拟机便会将该方法的循环回边计数器加1。
public void nlp(java.lang.Object);
Code:
0: iconst_0
1: istore_1
2: iconst_0
3: istore_2
4: iload_2
5: sipush 200
8: if_icmpge 21
11: iload_1
12: iload_2
13: iadd
14: istore_1
15: iinc 2, 1
18: goto 4
21: return在 JIT 编译过程中,编译器会识别循环的头部和尾部。上面这段字节码中,循环体的头部和尾部分别为偏移量为 11 的字节码和偏移量为 15 的字节码。编译器将在循环体结尾增加循环回边计数器的代码,来对循环进行计数。
当方法的调用次数和循环回边的次数的和,超过由参数 -XX:CompileThreshold 指定的阈值时(使用 C1 时,默认值为 1500;使用 C2 时,默认值为 10000),就会触发 JIT 编译。
分层编译和 JIT 触发
开启分层编译的情况下,-XX:CompileThreshold 参数设置的阈值将会失效,触发编译会由以下的条件来判断:
- 方法调用次数大于由参数
-XX:TierXInvocationThreshold指定的阈值乘以系数。 - 方法调用次数大于由参数
-XX:TierXMINInvocationThreshold指定的阈值乘以系数,并且方法调用次数和循环回边次数之和大于由参数-XX:TierXCompileThreshold指定的阈值乘以系数时。
// i为调用次数,b是循环回边次数
(i > TierXInvocationThreshold * s) ||
(i > TierXMinInvocationThreshold * s && i + b > TierXCompileThreshold * s) 上述满足其中一个条件就会触发即时编译,并且JVM会根据当前的编译方法数以及编译线程数动态调整系数s。
5. 参考资料
- Java即时编译器原理解析及实践
- 深入拆解 Java 虚拟机
- JVM-字节码解释执行引擎
- 深入理解Java虚拟机:JVM高级特性与最佳实践(第3版)周志明
