读书笔记,非纯原创
近期因为工作原因逐渐深入 Java 的世界。前几周组里一次部署服务器过程中,由于 JVM 内存参数设置错误,爆了内存引发了一次不大不小的事故。本系列文章滥觞于此。
1. JVM 数据类型
JVM 上运行的是和硬件、操作系统无关的二进制 .class 文件格式,操作的数据类型是原始类型(Primitive Types,也经常翻译为原生类型或者基本类型)和引用类型(Reference Types)。
1.1. Primitive 类型
和 Java 语言不同,JVM 的 primitive type 包括:数值类型(Numeric Type)、 布尔类型(Boolean Type) 和返回地址(ReturnAddress Type)三类。
- Numeric Type。又分为整数类型和浮点类型。整数类型包括:byet、short、int、long、char。浮点类型包括:float 类型、double 类型。
- Boolean Type。在 JVM specification 中,boolean 类型被映射成 int 类型。具体来说,“true”被映射为整数 1,而“false”被映射为整数 0。
- ReturnAddress 类型。是一个指向一条操作码指令的指针,现在已经算是被抛弃了。
Opcode vs Bytecode
- OPCODE: It is a number interpreted by your
machine (virtual or silicon)that represents the operation to perform - BYTECODE: Same as machine code, except, its mostly used by a
software based interpreter(like Java or CLR)
1.2. Reference 类型
Java 虚拟机中有三种引用类型:类类型(Class Types)、数组类型(Array Types)和接口类型(Interface Types)。这些引用类型的值分别由类实例、数组实例和实现了某个接口的类实例或数组实例动态创建。
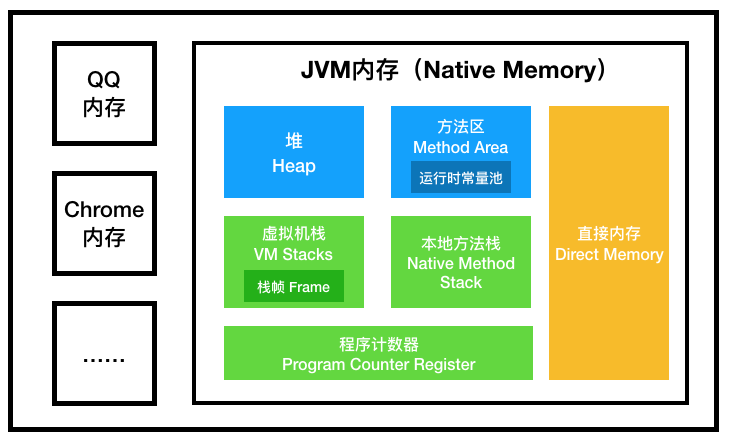
2. JVM 内存模型
在 JVM 规范中,并没有 JVM 内存模型这个术语,而是称为 Java run-time data areas(Java 运行时数据区)。
有些数据区是一直存在并被所有线程共享的,而有些则是线程私有的,随着线程开始而创建,结束而销毁。
- 线程共享:Heap、Method Area(包含运行时常量池)。
- 线程私有:JVM Stack、本地方法栈、pc 寄存器。
2.1. pc Register
- 每个线程有自己私有的 pc register。
- 如果当前执行 non-native method,即 Java 方法,pc register 指向正在执行的虚拟机字节码指令的地址;否则是 undefined。
2.2. VM Stack
- 每个线程有自己私有的 VM stack。
- 每当调用进入一个 Java 方法,JVM 会在当前线程的 Java 方法栈中生成一个 stack frame,用以存放局部变量以及字节码的操作数。这个栈帧的大小是提前计算好的,而且 JVM 不要求栈帧在内存空间里连续分布。 当退出当前执行的方法时,不管是正常返回还是异常返回,JVM 均会弹出当前线程的当前 stack frame,并将之舍弃。
- 如果线程请求的栈深度大于 JVM 所允许的深度,将抛出
StackOverflowError;如果Java虚拟机栈容量可以动态扩展,当栈扩展时无法申请到足够的内存会抛出OutOfMemoryError。
2.3. Native Method Stack
- Native method 是在 Java 中声明的可调用的使用 C/C++ 实现的方法。在 Java 源程序中以关键字
native声明,不提供函数体。使用 C/C++ 语言在另外的文件中编写,编写的规则遵循 Java 本地接口的规范 (简称 JNI,Java Native Interface)。使用 native method 是因为有些时候 Java 无法直接操作一些底层资源,只能通过C或汇编操作。 - JVM规范对 native method stack 中方法使用的语言、使用方式与数据结构并没有任何强制规定,因此具体的虚拟机可以根据需要自由实现它。
- 与 VM stack 一样,native method stack 也会在栈深度溢出或者栈扩展失败时分别抛出
StackOverflowError和OutOfMemoryError。
VM Stack vs Native Method Stack
VM stack为虚拟机执行 Java 方法(也就是字节码)服务,而 native method stack则是为虚拟机使用到的Native method 服务。有的Java虚拟机(譬如Hot-Spot虚拟机)直接就把本地方法栈和虚拟机栈合二为一。
2.4. Heap
- 在虚拟机启动时创建,被所有线程共享的一块内存区域,JVM specification 里规定所有 class instance 和 array 都应该在这里分配内存供运行时数据使用。
由于即时编译技术的进步,尤其是逃逸分析技术的日渐强大,栈上分配、标量替换优化手段已经导致一些微妙的变化悄然发生,所以说 Java 对象实例都分配在堆上也渐渐变得不是那么绝对了
- 受 GC 管理。为了更好地回收内存,一些基于 “经典分代” 理论的 GC 将 heap 分为新生代、老年代、永久代、
- 为了更快地分配内存,heap 中可以划分出多个线程私有的分配缓冲区 (Thread Local Allocation Buffer,TLAB),以提升对象分配时的效率。
- Java堆既可以被实现成固定大小的,也可以是可扩展的,不过当前主流的Java虚拟机都是按照可扩展来实现的(通过参数-Xmx和-Xms设定)。
2.5. Method
- 存储已被 JVM 加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等数据
- Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池表(Constant Pool Table),用于存放编译期生成的各种字面量与符号引用,这部分内容将在类加载后存放到 runtime constant pool中。Java语言并不要求常量一定只有编译期才能产生,运行期间也可以将新的常量放入池中
3. 案例分析:HotSpot 虚拟机
3.1. 对象的创建
当 JVM 遇到一条字节码 new 指令时,会经过以下步骤:
检查这个指令的参数是否能在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已被加载、解析和初始化过。如果没有,则先执行相应的类加载过程。
为 new object 分配内存: 类加载结束后,JVM 把一块确定大小的内存块从 heap 中划分出来。有以下两种分配内存的方法:
算法 内存状态 垃圾回收 Bump the Pointer 规整内存,所有被使用过的内存都被放在一边,空闲的内存被放在另一边,中间放着一个指针作为分界点的指示器 GC 有 compact 的能力,如使用 Serial, ParNew 等带压缩的 GC Free List 不整齐内存,已被使用的内存和空闲的内存相互交错在一起, GC 不带 compact,如使用 CMS 基于 sweep 算法的 GC
内存分配的线程安全
对象创建在虚拟机中是非常频繁的行为,即使仅仅修改一个指针所指向的位置,在并发情况下也并不是线程安全的,可能出现正在给对象 A 分配内存,指针还没来得及修改,对象 B 又同时使用了原来的指针来分配内存的情况。有两种方案:
- 对分配内存空间的动作进行同步处理 —— 实际上虚拟机是采用 CAS 配上失败重试的方式保证更新操作的原子性;
- 把内存分配的动作按照线程划分在不同的空间之中进行,即每个线程在 heap 中预先分配一小块内存,称为
本地线程分配缓冲(Thread Local Allocation Buffer,TLAB),哪个线程要分配内存,就在哪个线程的本地缓冲区中分配,只有本地缓冲区用完了,分配新的缓存区时才需要同步锁定。虚拟机是否使用 TLAB,可以通过-XX:+/-UseTLAB参数来 设定。
- 初始化 object:将分配到的内存空间(但不包括 object header)都初始化为零值,保证了 object 的实例字段在 Java 代码中可以不赋初始值就直接使用。
- 对 object header 进行必要的设置:例如这个对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希码(实际上对象的哈希码会延后到真正调用 Object::hashCode() 方法时才 计算)、对象的 GC 分代年龄等信息。这些信息存放在 object header 之中。
这只是 JVM 初始化的结束,还有…!
上面工作都完成后,从 JVM 的视角来看,new object 已经产生了。但是从 Java 程序的视角看来,object creation 才刚刚开始 —— 构造函数,即Class文件中的 <init>() 方法还没有执行,所有的字段都为默认的零值,对象需要的其他资源和状态信息也还没有按照预定的意图构造好。一般来说,new 指令之后会接着执行 <init> () 方法,按照程序员的意愿对对象进行初始化,这样一个真正可用的对象才算完全被构造出来。
// 确保常量池中存放的是已解释的类
if (!constants->tag_at(index).is_unresolved_klass()) {
// 断言确保是klassOop和instanceKlassOop
oop entry = (klassOop)*constants->obj_at_addr(index);
assert(entry->is_klass(),"Should be resolved klass");
klassOop k_entry = (klassOop)entry;
assert(k_entry->klass_part()->oop_is_instance(),"Should be instanceKlass");
instanceKlass * ik = (instanceKlass*)k_entry->klass_part();
// 确保对象所属类型已经经过初始化阶段
if (ik->is_initialized()&&ik->can_be_fastpath_allocated()) {
// 取对象长度
size_t obj_size = ik->size_helper();
oop result = NULL;
// 记录是否需要将对象所有字段置零值
bool need_zero = !ZeroTLAB;
// 是否在TLAB中分配对象
if (UseTLAB) {
result = (oop)THREAD->tlab().allocate(obj_size);
}
if (result == NULL) {
need_zero = true;
// 直接在eden中分配对象
retry:
HeapWord * compare_to = *Universe:heap()->top_addr();
HeapWord * new_top = compare_to+obj_size;
/* cmpxchg是x86中的CAS指令,这里是一个C++方法,通过CAS方式分配空间,如果并发失败,转到retry中重试,直至成功分配为止 */
if (new_top <= *Universe:heap()->end_addr()) {
if (Atomic:cmpxchg_ptr(new_top,Universe:heap()->top_addr(),compare_to)! = compare_to) {
goto retry;
}
result = (oop)compare_to;
}
}
if (result!= NULL) {
// 如果需要,则为对象初始化零值
if (need_zero) {
HeapWord * to_zero = (HeapWord*)result+sizeof(oopDesc)/oopSize;
obj_size -= sizeof(oopDesc)/oopSize;
if (obj_size>0) {
memset(to_zero,0,obj_size * HeapWordSize);
}
}
// 根据是否启用偏向锁来设置对象头信息
if (UseBiasedLocking) {
result->set_mark(ik->prototype_header());
}else{
result->set_mark(markOopDesc:prototype());
}
result->set_klass_gap(0);
result->set_klass(k_entry);
// 将对象引用入栈,继续执行下一条指令
SET_STACK_OBJECT(result,0);
UPDATE_PC_AND_TOS_AND_CONTINUE(3,1);
}
}
}3.2. 对象的内存布局
HotSpot虚拟机里,object 在 heap 中的存储布局可以划分为三个部分:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。
3.2.1. Header
- Mark Word:存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等。
- 类型指针:指向 type metadata 的指针。并不是所有的虚拟机实现都必须在对象数据上保留类型指针,即查找对象的元数据信息并不一定要经过对象本身
- 如果对象是一个 Java 数组,那在对象头中还必须有一块用于记录数组长度的数据
3.2.2. Instance data
对象真正存储的有效信息,即在程序代码里面所定义的各种类型的字段内容。字段存储顺序
存储顺序会受到虚拟机分配策略参数(-XX:FieldsAllocationStyle参数)和字段在 Java 源码中定义顺序的影响。
HotSpot 虚拟机默认的分配顺序为 longs/doubles、ints、shorts/chars、bytes/booleans、oops(Ordinary Object Pointers,OOPs)。可以看到:相同宽度的字段总是被分配到一起存放,在满足这个前提条件的情况下,在父类中定义的变量会出现在子类之前。3.2.3. Padding
不是必然存在的,也没有特别的含义,它仅仅起着占位符的作用。
HotSpot 虚拟机的自动内存管理系统要求对象起始地址必须是 8 字节的整数倍,换句话说就是任何对象的大小都必须是 8 字节的整数倍。对象头部分已经被精心设计成正好是 8 字节的倍数(1 倍或者 2 倍),因此,如果对象实例数据部分没有对齐的话,就需要通过对齐填充来补全。
3.3. 对象的访问定位
Java 程序会通过 stack 上的 reference 来操作 heap 上的具体对象。JVM specification 中关于 reference 类型的实现也是由虚拟机实现而定的,主流的访问方式主要有 使用句柄 和 直接指针 两种。
Pros & Cons
使用句柄来访问的最大好处就是 reference 中存储的是稳定句柄地址,在对象被移动(GC 时移动对象是非常普遍的行为)时只会改变句柄中的实例数据指针,而 reference 本身不需要被修改。
使用直接指针来访问最大的好处就是速度更快,它节省了一次指针定位的时间开销,由于对象访问在Java中非常频繁,因此这类开销积少成多也是一项极为可观的执行成本。
就 HotSpot 而言,它主要使用直接指针进行对象访问(有例外情况,如果使用了 Shenandoah 收集器的话也会有一次额外的转发),但从整个软件开发的范围来看,在各种语言、框架中 使用句柄来访问的情况也十分常见。
3.3.1. 使用句柄
Heap 中将可能会划分出一块内存来作为 句柄池,reference 中存储的是对象的句柄地址,句柄中包含了对象实例数据与类型数据各自具体的地址信息。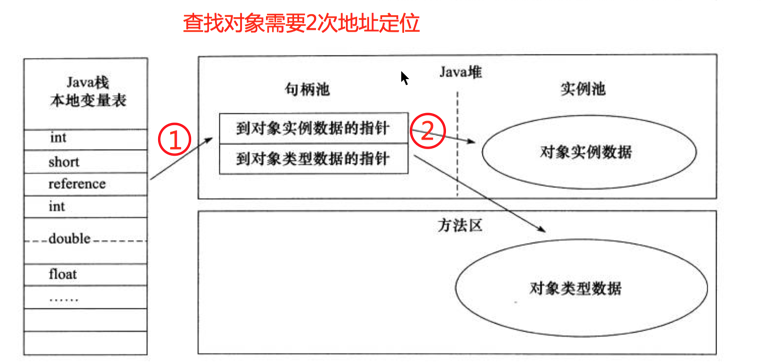
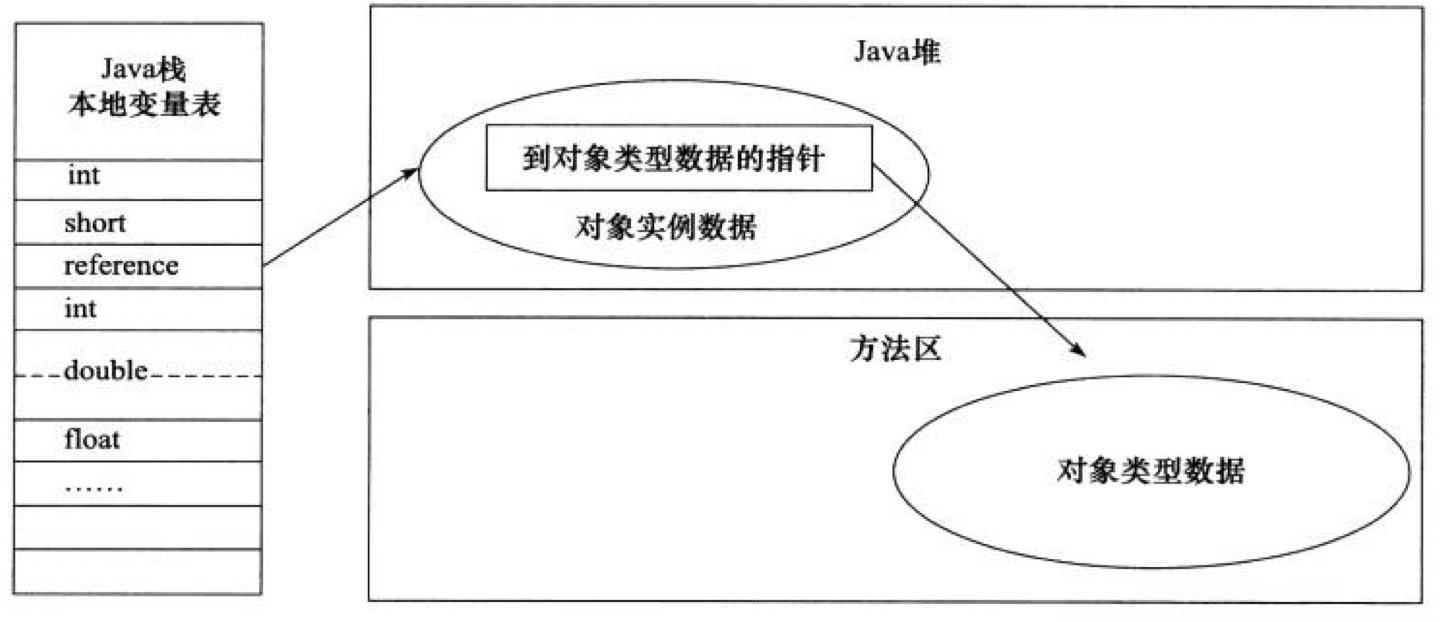
3.3.2. 直接指针
Reference 直接指向对象实例数据,在其内部放置了另一个访问对象类型数据的指针。
4. 参考资料
- JVM Specification: Chapter 2. The Structure of the Java Virtual Machine
- 深入理解Java虚拟机:JVM高级特性与最佳实践(第3版)周志明
- Difference between: Opcode, byte code, mnemonics, machine code and assembly
- JVM规范系列第2章:Java虚拟机结构
- 深入拆解 Java 虚拟机

