阅读 Java Core 的过程中遇到了 Code Point、Code Unit等术语,借机深挖了编码相关知识。此篇为笔记整理,非完全原创。
1. 字符编码小史
TL;DR. 如果对字符编码有一定了解,可以直奔文末总结部分。
1.1. ASCII
开始计算机只在美国用,工程师们用 1 个字节来存储每个字符,其中 8 bits 可以组合出 $2^8 = 256$ 种不同的状态(实际只使用 7 位,最高位置 0)。
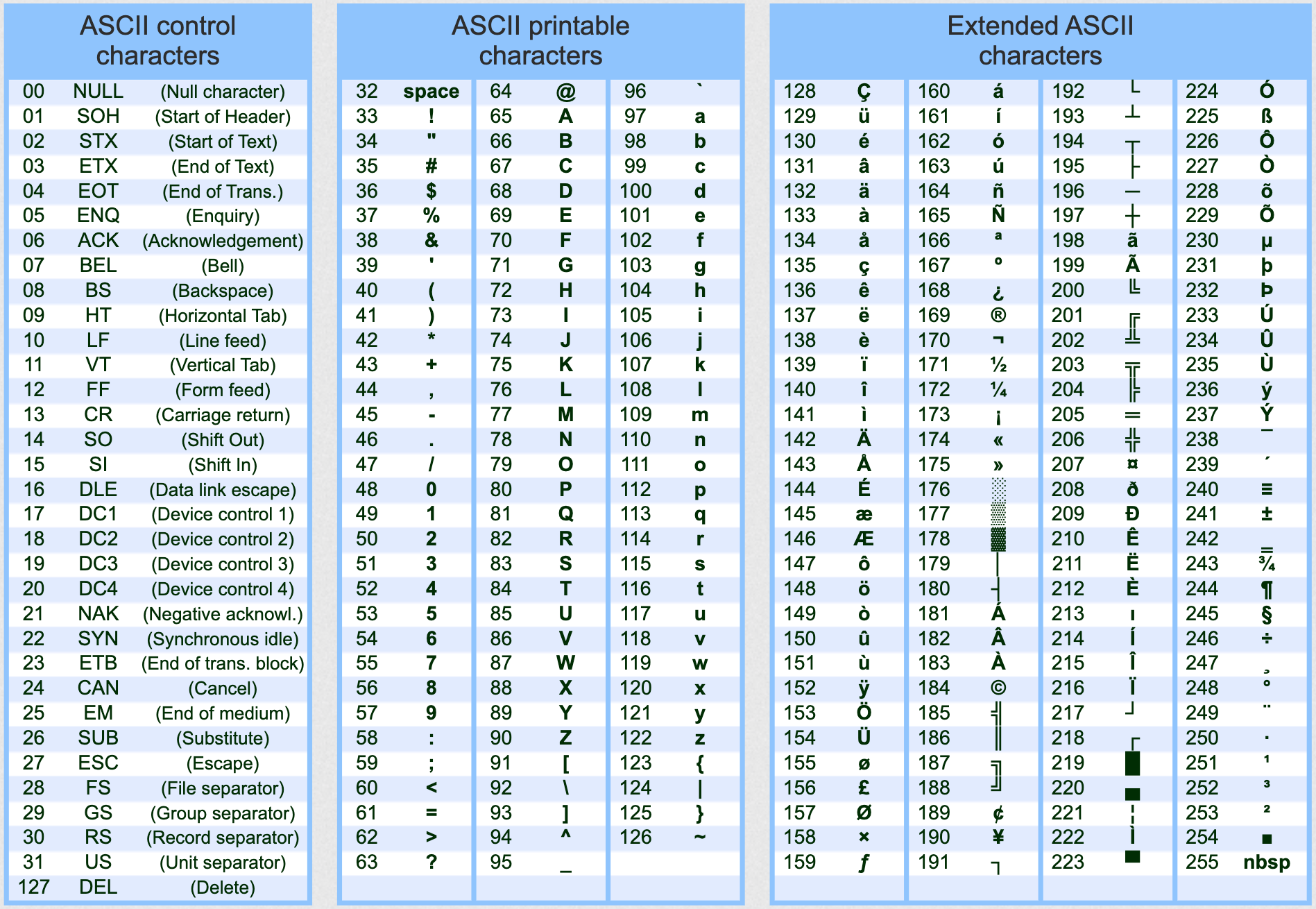
他们把其中的编号从 0 开始的 32 种状态分别规定了特殊的用途,一旦约定好的这些字节传到终端、打印机,就要做约定的动作。这前 32 个及 127 号 DEL (共33个) 控制字符 (control characters) 多是为当时使用而现在很少见到的设备而设计的,今日已经很少被使用。
关于 BeL 控制字符[1]
在 ASCII 编码中,BEL 是个比较有意思的编码。BEL 用一个可以听得见的声音来吸引人们的注意,既可以用于计算机,也可以用于周边设备(比如打印机)。注意,BEL 不是声卡或者喇叭发出的声音,而是蜂鸣器发出的声音,主要用于报警,比如硬件出现故障时就会听到这个声音,有的计算机操作系统正常启动也会听到这个声音。蜂鸣器没有直接安装到主板上,而是需要连接到主板上的一种外设,现代很多计算机都不安装蜂鸣器了,即使输出 BEL 也听不到声音,这个时候 BEL 就没有任何作用了。
他们又把阿拉伯数字、大小写英文字母、标点符号、运算符号等分别用连续的字节状态表示,这 95 个字符称为可显示字符 (printable characters)。
这样计算机就可以用不同字节来存储英语的文字了,这个编码方案就是 ASCII码 (American Standard Code for Information Interchange)。
后来计算机发展越来越广泛,世界各国为了可以在计算机保存他们的文字,他们决定采用 127 号之后的空位来表示这些新的字母、符号,还加入了很多画表格时需要用下到的横线、竖线、交叉等符号,序号一直编到了最后一个状态 255。从 128 到 255 这一页的字符集被称扩展字符集 (Extended ASCII Characters)。但原有的编号方法,已经再也放不下更多的编码。
1.2. 混乱时期
英语字母用128个符号编码就够了,但是 1 个字节用来表示其他语言还是略显紧缺。
等中国人得到计算机时,已经没有可以利用的字节状态来表示汉字,况且有 6000 多个常用汉字需要保存。于是国人就自主研发,把那些 127 号之后的奇异符号们直接取消掉。规定:一个小于 127 的字符的意义与原来相同,但两个大于 127 的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从 0xA1 用到 0xF7,后面一个字节(低字节)从 0xA1 到 0xFE,这样我们就可以组合出大约 7000 多个简体汉字了。在这些编码里,我们还把数学符号、罗马希腊的字母、日文的假名都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的”全角”字符,而原来在 127 号以下的那些就叫”半角”字符了。这种汉字方案叫做 GB2312,是对 ASCII 的中文扩展。
但中国的汉字太多了,后来还是不够用,于是干脆不再要求低字节一定是 127 号之后的内码,只要第一个字节是大于 127 就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的内容。扩展之后的编码方案被称为 GBK 标准,**GBK** 包括了 GB2312 的所有内容,同时又增加了近 20000 个新的汉字(包括繁体字)和符号。后来少数民族也要用电脑了,于是我们再扩展,又加了几千个新的少数民族的字,**GBK** 扩成了 **GB18030**。从此之后,中华民族的文化就可以在计算机时代中传承了。
因为当时各个国家都像中国这样搞出一套自己的编码标准,结果各国在未达成统一标准的情况下各行其是,导致同一个编码可以被多重定义。比如,130 在法语编码中代表了**é,在希伯来语编码中却代表了字母Gimel (ג)**,在俄语编码中又会代表另一个符号。同一个二进制数字可以被解释成不同的符号。因此要想正确解码一个文本文件,就必须知道它的编码方式,否则会出现乱码。比如想让电脑显示汉字,就必须装上一个”汉字系统”,专门用来处理汉字的显示、输入的问题,装错了字符系统,显示就会乱了套。
1.3. Unicode 字符集
世界亟需一套统一编码体系将世界上所有的符号都纳入其中。就在这时,一个叫 ISO(国际标准化组织)的国际组织决定着手解决这个问题。他们采用的方法很简单:废了所有的地区性编码方案,重新搞一个包括了地球上所有文化、所有字母和符号的编码,给予每一个符号一个独一无二的 id!这便是 Unicode (Universal Multiple-Octet Coded Character Set),每个符号对应的数值 id 称为码点 (Code Point),这个庞大的字符集可以编码 $[0_{hex}, 10FFFF_{hex}]$ 共 $1114112$ 个字符。
Unicode 开始制订时,计算机的存储器容量极大地发展了,空间再也不成为问题。于是 ISO 就直接规定必须用两个字节,也就是 16 位来统一表示所有的字符,对于 ASCII 里的那些”半角”字符,Unicode 包持其原编码不变,只是将其长度由原来的 8 位扩展为 16 位,而其他文化和语言的字符则全部重新统一编码。由于”半角”英文符号只需要用到低 8 位,所以其高 8 位永远是 0,因此这种大气的方案在保存英文文本时会多浪费一倍的空间。
举个例子,I、t 在 Unicode 编码总共占用了 4 bytes,而 ASCII 中只需要一半即 2 bytes。对比二进制码,可以发现,其前9位都是0!真是浪费硬盘,浪费流量!这也就为后来的变长编码方案,UTF-8的出现埋下了伏笔。
// ASCII 十六进制编码
I 49
t 74
// 严格按照 ASCII 的二进制存储
I 01001001
t 01110100
// Unicode 十六进制编码
I 0049
t 0074
// 严格按照 Unicode 的二进制存储
I 00000000 01001001
t 00000000 01110100然而 Unicode 只规定了符号的唯一 id,并没有规定这个二进制代码应该如何存储。于是面向传输的众多 UTF(UCS Transfer Format) 标准出现了,顾名思义,**UTF-8** 就是每次 8 个 bits 传输数据,而 UTF-16 就是每次 16 个 bits。我们将在下一节展开叙述。
1.3.1. 字符集和字符编码
从 Unicode 到 UTF 并不是直接对应,而是要过一些算法和规则来转换。转换规则并不是本文的重点,我们来看个例子[2]。
音乐符号 𝄞 的 Unicode 码点(code point) 是U+1D11E,在三种字符编码下分别表示为:
| Character Encoding | Code Unit | Encoding value | Encoded value Description |
|---|---|---|---|
| UTF-8 | 8-bit | 0xF0 0x9D 0x84 0x9E | 4 bytes. A sequence of 4 code units each 8-bits in length |
| UTF-16 | 16-bit | 0xD834 0xDD1E | 4 bytes. A sequence of 2 code units each 16-bits in length |
| UTF-32 | 32-bit | 0x0001D11E | 4 bytes. A sequence of 1 code units each 32-bits in length |
不同的二进制存储方式有不同的最小存储单元,如 UTF-8 以 8 bits 作为最小编码单位,即一个字符编码长度在 UTF-8中只可能为 8、16、18 或 32 这些 8 的整数倍,故 8 被称为 UTF-8 的**码元 (code unit)**。相似地,UTF-16 和 UTF-32的码元是 16 和 32。注意只有 UTF-32 的二进制实际编码和 Unicode 码点一致。
1.3.2. UTF-? —— 编码的学问
这么多种 Unicode 的编码方式,在使用时有什么区别呢?先来看看各种编码方式都编了些什么。
有人可能会产生疑问:**UTF-8** 既然能保存那么多文字符号,为什么国内还有这么多使用 GBK 等编码的人?因为 UTF-8 等编码中文占电脑空间比较多,需要 3 个字节,而 GBK 编码只需要 2 个。但对于欧美地区一些以英语为母语的国家,**UTF-8** 无疑是一个好的选择,因为它和 ASCII 一样,一个字符只占一个字节,没有任何额外的存储负担;但是对于中日韩等国家来说,**UTF-8** 实在太冗余 —— 一个字符要占用 3 个字节,存储和传输的效率不但没有提升,反而下降了。所以欧美人民常常毫不犹豫的采用 UTF-8,而我们却老是要犹豫一会儿。
同时变长字节会带来效率问题:**UTF-8的一个问题就在于其是变长字节表示,因此无论是计算字符数,还是执行索引操作效率都不高。为了解决这个问题,常常会考虑把 **UTF-8 先转换为 UTF-16 或者 UTF-32 后再操作,操作完毕后再转换回去。而这显然是一种性能负担。
最后值得一提的是,**UTF-8**是在互联网上使用最广的一种Unicode的实现方式。
2. 总结
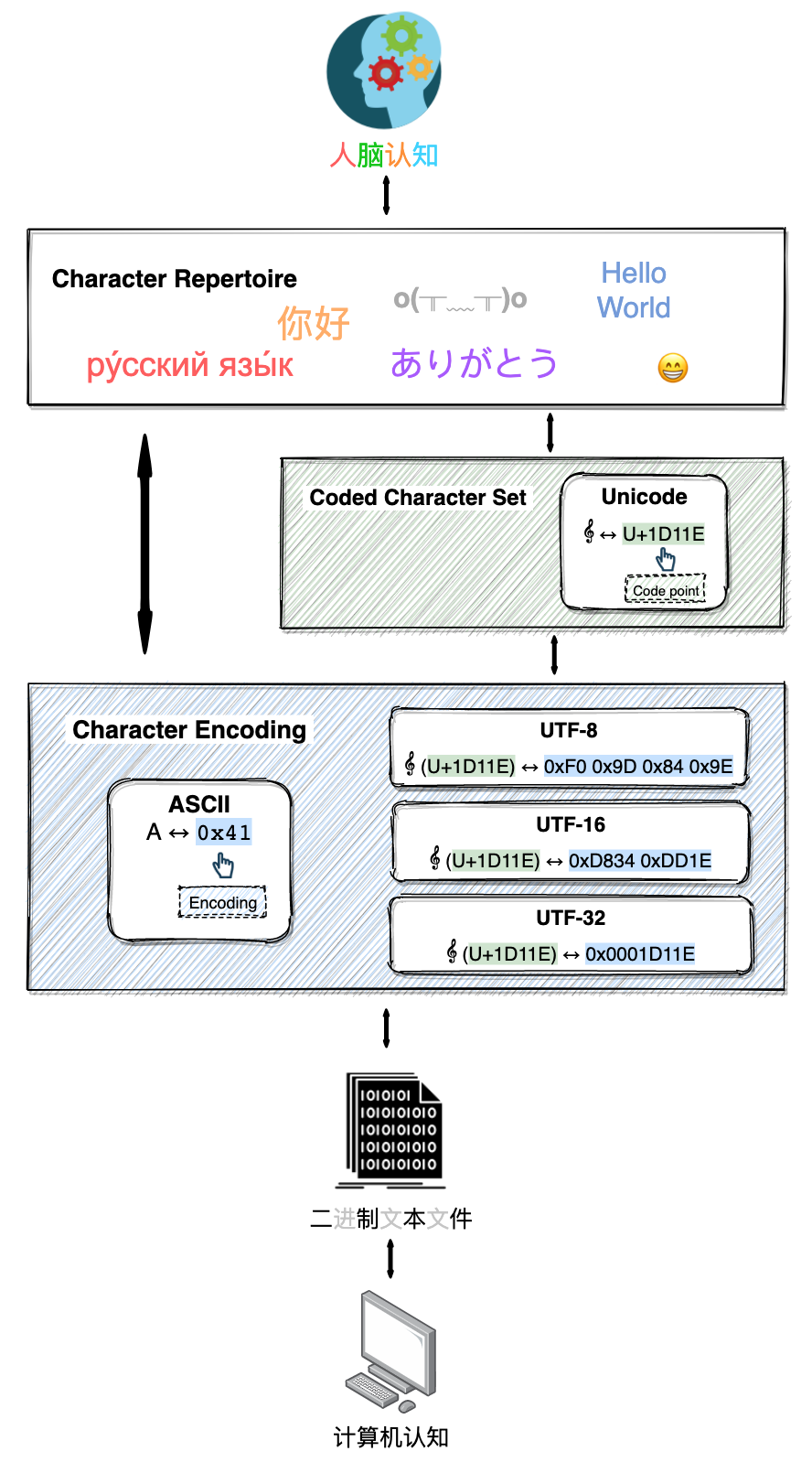
一图蔽之,人脑可以识别汉字、阿拉伯数字、emoji 等字符,而计算机只能存储和处理诸如010001的二进制序列。编码字符集 (Coded Character Set)和字符编码 (Character Encoding)便是跨越鸿沟的这座桥梁。
本质上,编码字符集是一个映射,其规定了字符和数值类型间的对应关系,数值类型被称为码点。Unicode 就是一个编码字符集,如下图中音乐符号 𝄞 在 Unicode 中的 码点是U+1D11E。
但码点仅仅是字符在编码字符集中的 id,并不是计算机实际的二进制存储,于是出现了UTF-8、UTF-16等字符编码,即基于码点,规定某个文字和二进制编码之间的一一对应关系。值得注意的是,ASCII 将字符直译成二进制编码。