本文是编码系列文章的延伸,建议先食用 编码那些事儿一文。
1. 什么是BOM?
BOM是用来判断文本文件是哪一种 Unicode 编码的标记,其本身是一个 Unicode 字符 \uFEFF,位于文本文件头部,让我们可以根据文件头部的几个字节和上面的表格对应来判断该文件是哪种编码形式。
在不同的 Unicode 编码中,对应的bom的二进制字节如下:
| BOM Bytes | Encoding |
|---|---|
| FE FF | UTF16BE |
| FF FE | UTF16LE |
| EF BB BF | UTF8 |
2. BOM = BOMB
BOM尽管起到了标记文件编码的作用,但是它并不属于文件的内容部分,不同软件对于它有不同的处理逻辑,这种不一致的处理逻辑带来了一系列问题。
2.1. 案例 1:用 Excel 打开没有 BOM 的文件
我们用创建一个没有 BOM 头的 csv 文件,然后以 UTF-8 编码保存。记事本打开可以正常显示,但 excel 却识别出错,也就是说 excel 无法识别没有 BOM 头的文件。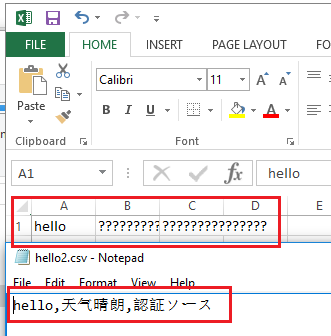
2.2. 案例 2:用 PHP 处理有 BOM 的文件
对于 PHP 来说,BOM 是个大麻烦: PHP 在设计时就没有考虑 BOM 的问题,也就是说他不会忽略 UTF-8 编码的文件开头 BOM 的那三个字符。所以在读取、包含或者引用这些文件时,会把 BOM 作为该文件开头正文的一部分。由于必须在 <?或者 <? php后面的代码才会作为PHP代码执行,所以这三个字符将被直接执行(显示)出来。由此造成即使页面的 top padding 设置为 0,也无法让整个网页紧贴浏览器顶部,因为在 html 一开头仍有这3个字符!
Best Practice
类似 Windows 自带的记事本等软件,在保存一个以 UTF-8 编码的文件时,会在文件开始的地方插入 UTF-8 BOM。记事本等编辑器通过它来识别这个文件是否以 UTF-8 编码(当然即便没有 UTF-8 BOM 记事本也能通过其它方式正确识别 UTF-8 编码)。BOM 在记事本中是看不到的。因此在编辑、更改任何文本文件时,请务必使用不会乱加 BOM 的编辑器。Linux 下的编辑器应该都没有这个问题。Windows 下,避免使用记事本对代码进行更改。

